关于中美AI 竞争的差距,我可能真的说错了
本文来自微信公众号: MacTalk ,作者:池建强,原文标题:《关于中美 AI 竞争的差距,我可能真的说错了》
比如我和一些做基模的专业同学沟通,他们的判断——编程模型差5%-10%,整体上可能是3-6个月的差距——这些就是基于他们自己的专业判断,有基线有标准,甚至放到国际评测榜单上,也是类似的结论。这是个专业判断。甚至在OCR开源模型这个领域,PaddleOCR-VL-1.5就是做到了SOTA。
但涉及到个人,感受就千差万别了。有用户说,中国差在了硬件上,有的说算力不够,模型也不可能好到哪儿去。有的普通用户日常让AI助手解决生活里的一些问题,中文的豆包、千问、DeepSeek等模型,就是比ChatGPT和Gemini回答的好啊。
即便是同一个领域——比如编程——体感也不一样。
有的用户用来做补全和完成一些简单的模版任务,MiniMac M2.1就是很好啊,干得漂亮还便宜。有的用户呢,开多个Agent做多任务并行,完成复杂的编程实践,这时候Claude的优势就发挥出来了,所以他们会认为CC比国内模型强大很多。
现在看起来,这是个很难定义的衡量标准。就目前的大趋势来说,基模能力整体上中国落后美国,这是没问题的。落后几个月,不好说,但不会超过一年,甚至中国有些领域是领先的,比如开源模型。2026如果中国解决了一部分算力问题,我预测这个差距会进一步缩小,因为Scaling Law的效果已经越来越不明显了,预训练和强化训练也开始呈现疲态,AI厂商已经开始追逐第三范式Online Learning了。这对追赶者来说,是好事。
还有一点无法忽视,目前的模型越来越强,99%的用户根本没办法压榨大模型的能力极限。也就是说,模型能力花了100倍的功夫,增加了5%的能力,大部分用户都感知不到。
比如周五发布的Opus 4.6确实很强,但是有多强?目前我试了几个项目,感觉前一代也能解决啊。想榨干模型的能力,几乎是不可能的。甚至想找一些前一代模型搞不定、但新模型却能轻松搞定的案例都很难了。
目前关于新模型(Opus 4.6)能力最有说服力的故事,是Anthropic的Nicholas Carlini谈Opus 4.6的那篇:用一支并行协作的Claude团队来构建一个C编译器——这可以看作是Anthropic团队在自动化软件开发方向的一次系统性实践:Building a C compiler with a team of parallel Claudes
https://www.anthropic.com/engineering/building-c-compiler
这是一次用多实例Claude自动协作、从零构建可编译Linux内核的C编译器的实验,我觉得99%的工程师别说完成实验了,设计实验都困难。
这个事有多复杂呢?构建一个agent teams,让多个Claude实例在几乎没有人类干预下,在同一个代码仓库长期并行地协作开发。作者用16个Claude,在将近2000次Claude Code会话和约2万美元API花费下,从零写出了一个基于Rust的C编译器,可以在x86、ARM、RISC‑V上编译Linux 6.9,还能编译QEMU、FFmpeg、SQLite、Postgres、Redis,并在大多数编译器测试套件上达到99%通过率。
首先,用一个“无限循环”脚本让单个Claude永不停机地反复拉起自己,每次读同一套agent prompt,持续拆解任务、写代码、再选下一步要做什么。然后扩展成并行架构:多个Docker容器各自克隆同一上游仓库,用简单的“写锁文件+git同步”避免多个agent抢同一任务,通过频繁pull/merge解决冲突,没有额外的调度/编排agent,每个Claude自主决定下一步要做啥。随着项目扩展,作者逐渐引入了更完备的测试与CI,让Claude依靠高质量测试和日志来自我定位问题。
我的理解也就能到这里了。
这个实验充分展示了Opus 4.6能力。之前的版本勉强能做出能跑小demo的编译器,但不能编译大型项目;Opus 4.6在这个scaffold下第一次跨过了“能编译真实世界大型项目”的门槛。
不过编译器依然有硬伤:缺少16位x86代码生成器,只能在引导阶段依赖GCC;汇编器和链接器还不稳定;对某些项目仍编译失败;生成的代码性能显著差于GCC即便后者不开优化;Rust代码质量远逊于顶级人类工程师,而且一旦尝试继续修bug或加特性,很容易破坏已有功能。
这是下一代Opus要解决的问题。
事实上每一代模型都在拓展与开发者协作的方式:从IDE补全,到根据注释写函数,再到Claude Code这种结对编程型agent,如今agent teams展示了“全自动完成复杂项目”的可能。
这让人们看到了规模性使用Agent的可能性,但目前这种可能性也只有顶级的AI工程师能够触碰,大部分工程师都在做智能代码补全,根据注释模板生成代码,处理文件,做单一Agent任务等等。所以体感也是完全不同的。
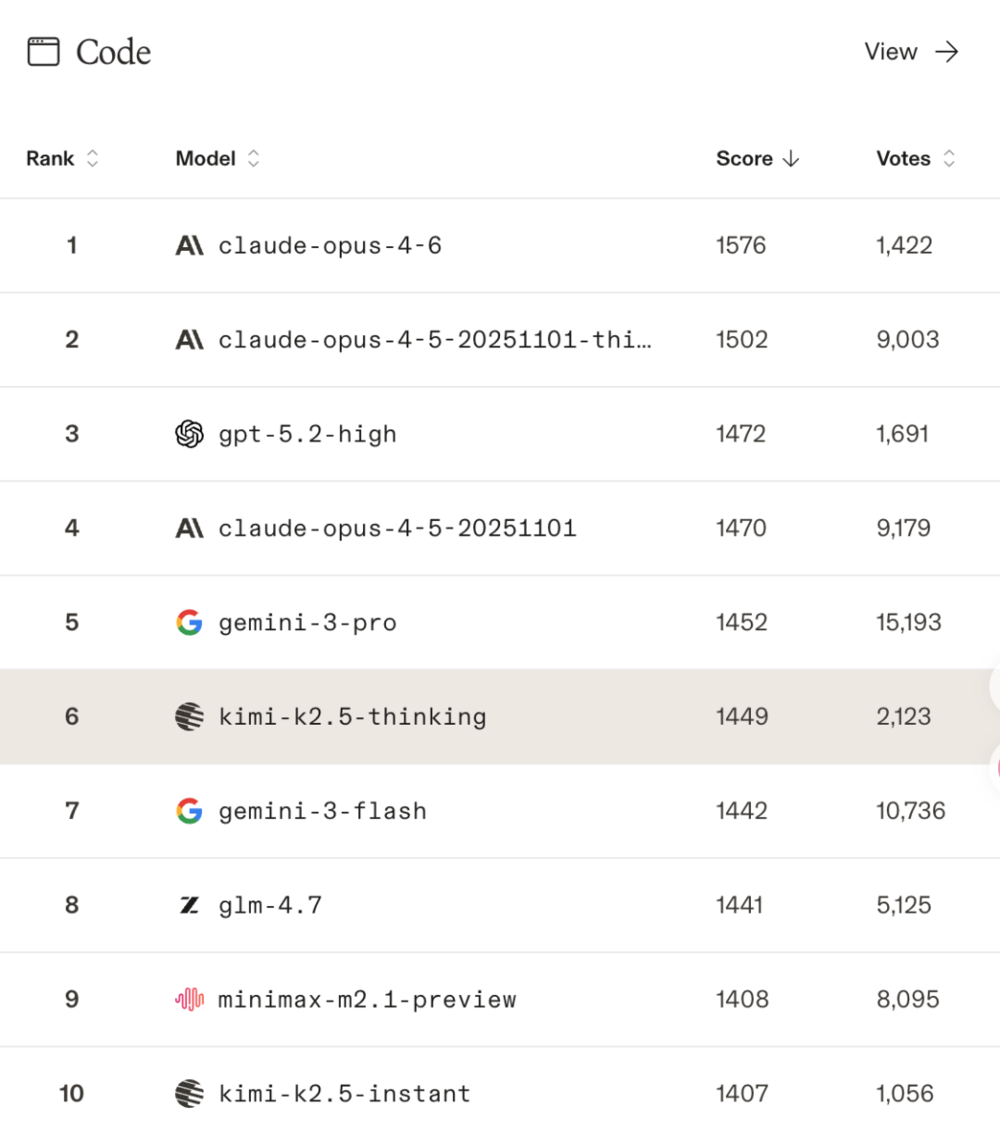
那么类似LMArena的评测榜单有没有价值呢?肯定有啊,比如最近中国模型在编程领域的成绩就很不错。前五名是美国模型,后五是中国模型。有人说,那不是可以刷榜吗,针对性训练等等。这个其实越来越难了,因为LMArena也在进行,不仅仅有机器评测,有升级的训练场,有案例测试,还有人工投票,等等。
你看文本大模型的能力,目前前十就剩下一家中国模型,还是百度的ERNIE-5.0,其他家怎么不刷上去呢?
另外中美的商业模式也不一样,美国AI公司对C端卖订阅费用,对B端卖API赚钱,非常明确和简单,现在OpenAI已经开始探索第三种方式——广告业务了。
国内呢,就复杂得多,豆包是国内最大用户量的AI产品吧,普惠,一分钱不收。千问和元宝为了追赶豆包,还得补贴用户红包和奶茶,抢占市场。类似火山引擎和百度AI云这样的toB服务,倒是一样的,企业想用AI,还是买API和服务比较稳妥。
另外,为什么国外顶级模型都是闭源的,中国都是开源的?
ChatGPT、Gemini、Claude等在模型研发上投入了数十亿美元,通过闭源(API授权制),它们可以建立极高的商业壁垒,确保每一笔算力投入都能通过订阅费或API调用费获得回报。
国内AI公司本来就是后发,需要通过开源来快速吸引开发者,降低全球用户的试用门槛,从而在短时间内建立起足以抗衡美国的开发者生态。另外,面对算力和芯片限制,中国企业也倾向于分布式创新。开源能汇聚全球开发者的反馈,在算法优化和推理效率上寻找突破。第三,开源对中小企业也更友好,中国厂商通过提供“好用且免费/低价”的开源权重,能迅速渗透到制造业、政务等垂直细分市场,以普及率换取未来的商业地位。
这里面还涉及地缘政治的问题,咱就不细讲了。总之中国的环境其实要复杂的多,美国就更直接、简单。未来两边肯定是螺旋式交织上升,具体AI能发展到什么程度,如何改变世界的格局和商业模式,改变人们的生活……
我想,五年之内见分晓吧。
。