AI学霸遇专家级考试:GPT-4o仅考2.7分,人类终极测试戳破能力假象| 一起读顶刊| 人工智能
本文来自微信公众号: 生态学时空 ,作者:复旦赵斌,原文标题:《【本周Nature】AI学霸遇专家级考试:GPT-4o仅考2.7分,人类终极测试戳破能力假象 | 一起读顶刊 | 人工智能》
打开ChatGPT写论文、用Gemini解数学题,AI仿佛无所不能,甚至在不少测试中拿下高分。但如果给AI出一套研究生级专家考题,它还能稳坐学霸宝座吗?
本周《自然》杂志报道的人类终极考试(HLE),用2500道全球专家命题,给前沿AI来了一场硬核摸底。结果颠覆认知:GPT-4o仅得2.7分(满分100),最厉害的AI也没超过8分。者让我们重新思考:AI的厉害,到底是真本事还是假繁荣?
一、传统AI测试失效:不是AI太聪明,是考题被摸透了
我们总用基准测试衡量AI能力,就像给AI做期末考试。但这些测试现在越来越不管用了,核心问题出在两点:
1.基准饱和:AI把考试范围背熟了
早期AI在测试中磕磕绊绊,但现在的AI不仅训练数据覆盖全网,甚至能在测试时在线搜答案。久而久之,AI摸清了传统测试的出题逻辑,比如MMLU、MATH这些热门基准,顶尖AI的准确率早就超过90%(图1b蓝色区域),就像学霸把小学试卷做到满分,再考已经看不出真实水平——这就是基准饱和。
2.答案能作弊:高分≠真智能
传统测试的很多题目,答案能在网上直接搜到。AI给出的正确答案,可能不是靠推理,而是靠检索+记忆,就像考试时偷偷翻书,看似答对了,实则没掌握核心能力。
为了破解这个难题,人工智能安全中心联合全球专家,打造了HLE——一套专门难住AI的专家级基准,堪称AI的高考压轴题。
二、HLE:全球专家出题,AI想作弊都难
HLE的2500道题,可不是随便编的,每一道都带着反AI作弊的设计:
1.出题天团:50国专家共建,题目够专
题目来自50个国家、500多所机构的近1000名专家,涵盖数学、生物、物理、计算机等8大领域,每道题都需要研究生级专业知识才能解答。比如数学题要靠深层逻辑推导,化学题涉及复杂反应机理,根本没法靠简单检索找到答案。
2.设计严格:三重把关,杜绝钻空子
先过AI关:提交的题目会先让顶尖AI试做,AI能答对的直接淘汰;
再经专家审:两轮人类评审,确保题目精确、无歧义、有唯一答案;
分公私题库:公开2500道题供测试,保留私有题库,防止AI死记硬背答案(也就是过拟合)。
3.题型限制:答案可验证,避免瞎忽悠
HLE只有选择题和简答题,答案明确且能自动验证,杜绝AI靠话术忽悠得分。但这也带来一个小局限:人文社科题目占比仅9%,远低于STEM领域的82%——因为人文题大多是开放式的(比如如何评价某历史事件),没有统一答案,没法纳入测试。
三、看懂文中的一张图,理解HLE的核心价值
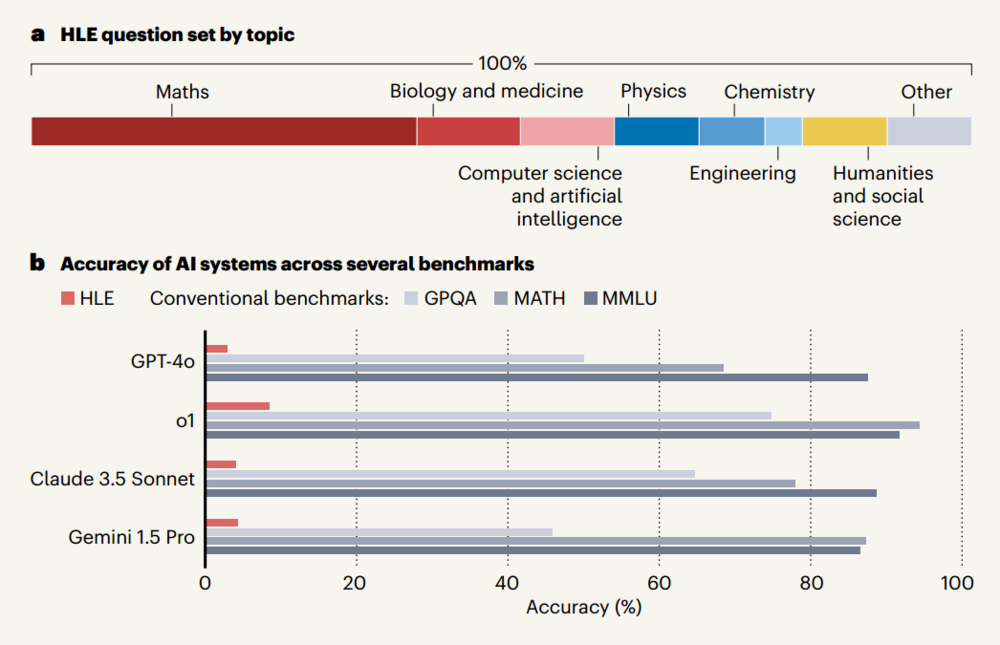
图1利用专家级题目测试前沿人工智能系统。
图1a清晰展示了这套专家级测试的题目构成:
1.题目覆盖:8大领域,全球专家共建。HLE的2500道题不是随便编的,而是来自50个国家、500多所机构的近1000名专家贡献,覆盖8个核心学术领域——数学、生物与医学、物理、计算机科学与AI、化学、工程学、人文社科、其他领域,真正做到了跨学科专家级。
2.比例差异:STEM占82%,人文社科仅9%。从图中能明显看到:数学占比最高(约41%),加上生物与医学(11%)、物理(9%)、计算机科学与AI(10%)、化学(7%)、工程学(4%),STEM(科学、技术、工程、数学)类题目合计占比达82%;人文社科(如历史、社会学等)仅占9%,是占比最低的类别之一。
3.背后原因:题目设计标准决定的必然结果。文章明确解释了这种比例差异的核心逻辑:HLE的题目必须满足答案明确、可自动验证(比如数学题有唯一解、化学题有固定反应类型),而人文社科的专家级问题大多是开放式的(比如如何评价某历史事件的影响),没有统一标准答案,无法纳入HLE的自动评分体系。这也导致HLE只能优先选择STEM类题目——这类题目能清晰区分对与错,真正测出AI的硬知识和硬推理能力。
图1b是AI在普通测试和专家测试中的表现对比图,横坐标是准确率(0%-100%),纵坐标是4款前沿AI模型(GPT-4o、o1、Claude 3.5 Sonnet、Gemini 1.5 Pro),核心是用数据揭露“AI在专家级问题前的真实水平”:
1.传统基准:AI已接近满分,测试失效
图中GPQA、MATH、MMLU是3个常用的传统AI基准(类似AI的期末考试),能看到4款AI在这些测试中表现极佳:
多数模型准确率超过60%,部分甚至接近80%-100%;
这就是文章说的“基准饱和”——AI在传统测试上分数太高,已经测不出它们的真实能力差距,就像学霸在小学试卷上都考100分,无法区分谁更厉害。
2.HLE基准:AI集体考砸,最高仅8%准确率
而到了HLE这个专家级测试,AI的表现堪称断崖式下跌:
4款顶尖AI的准确率都在个位数徘徊:GPT-4o仅2.7%,Claude 3.5 Sonnet 4.1%,Gemini 1.5 Pro 4.6%,表现最好的o1也才8%;
这个数据直接印证了文章结论:即使是现在最先进的AI,在“需要研究生级专业知识”的专家级问题上,还处于“几乎不会”的水平——比如GPT-4o在HLE上的分数,相当于100分试卷只考了2.7分,完全暴露了AI在深层专业能力上的短板。
3.关键对比:HLE才是AI的真实能力照妖镜
图1b用传统基准的高分数和HLE的低分数形成强烈反差:
传统基准的高分数,是因为AI能通过检索公开答案、记忆训练数据拿到高分,并非真的具备专家级思维;
HLE的低分数,是因为题目都是原创、无公开答案、需要深度推理(比如数学的深层逻辑推导、物理的复杂实验分析),AI没法走捷径,只能靠真实能力作答——这也正是HLE的设计目的:打破基准饱和,测出AI的真实专家级能力。
四、HLE的价值:不止是难住AI,更是重新定义AI能力
虽然HLE刚发布就引发争议,但它的意义远超一场考试:
HLE让AI公司没法再靠传统基准炫技,倒逼它们提升真实推理能力。比如HLE发布后,GPT-5在测试中准确率提升到25%,虽仍不高,但相比GPT-4o的2.7分,进步肉眼可见——这就是标尺的作用,让AI的进步有了明确方向。
2.暴露AI的核心短板
HLE测试还发现,AI不仅不会做难题,还不知道自己不会:明明答案错了,却自信满满;给它更多计算资源,也没法转化为更高准确率。而人类专家的核心能力,恰恰是知道自己不知道,能判断问题是否合理,甚至提出新问题——这些都是AI目前欠缺的。
3.引发深层思考:什么才是真智能?
HLE的局限性也让我们反思:真正的专家级智能,不是能答对所有封闭题,而是能应对开放式、无标准答案的复杂问题——比如写一篇有洞见的论文,设计一个创新实验,甚至重新定义一个研究方向。这些能力,靠HLE这类测试测不出来,但却是人类智能的核心。
五、核心认知:AI的专家级,和人类专家还差着一道鸿沟
HLE给我们的最大启发,不是AI不行,而是AI的厉害,和我们理解的专家能力不是一回事:
AI的强:在于处理海量数据、检索公开信息、快速完成重复任务;
人类专家的强:在于深度推理、批判性思维、不确定性判断,以及提出新问题的创造力。
就像HLE的设计者所说,这个测试的终极目标,是让自己过时——倒逼AI发展出真正的专家级思维,而不是停留在检索+记忆的层面。
结尾:AI的进步,需要难住它的测试
AI不是万能的,HLE用一场惨考告诉我们:智能的本质不是答对题,而是会思考。未来,AI可能会在HLE上拿到更高分,但我们更该期待的,是能像人类专家一样,既能破解难题,又能提出新题的AI。
而对我们来说,与其纠结AI能考多少分,不如学会利用AI的高效,同时守住自己的深度思考——毕竟,真正推动世界进步的,从来不是能记住答案的工具,而是能提出问题、解决未知的人类智慧。
https://doi.org/10.1038/s41586-025-09962-4
https://doi.org/10.1038/d41586-025-04098-x
。