要我说,大模型这圈子最近有点意思。大家不再只顾着吹模型多牛,反而开始操心“怎么让这大家伙老老实实干活”这种接地气的问题了。
这不,前两天杭州一个叫“SGLang AI金融π对”的技术活动,聊的就是这个。全场没太多虚的,核心就透了一件事:以后想把DeepSeek、Qwen这些模型跑在国产昇腾卡上,可能跟用英伟达一样简单了。
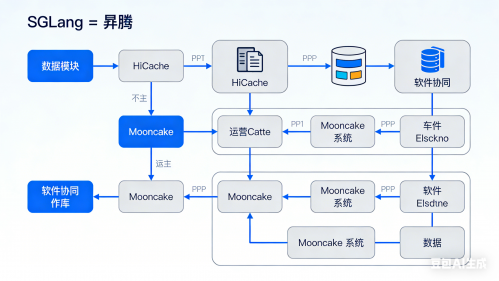
SGLang 与昇腾合作 (1)
一、到底发生了啥?
简单讲,就是搞推理引擎的SGLang团队,和搞昇腾硬件的华为团队,俩人“勾兑”好了。
现在,昇腾已经作为官方原生支持的后端,直接并入了SGLang的主代码库。对我们这些用的人来说,意味着什么呢?就是你从GitHub上拉下最新的SGLang,你的模型(比如DeepSeek-V3.2)就能直接在昇腾的机器上跑起来,不用你吭哧吭哧改任何模型代码,也不用装什么特殊插件。
以前那种“为了一块卡,重写一半代码”的麻烦事,现在可以省省了。
二、他们到底解决了什么“痛点”?
光能跑不算本事,跑得好才行。这次他们主要解决了Agent(智能体)应用带来的几个头疼事:
-
对付“长文本失忆症”:Agent动不动就要分析几百页文档,显存根本不够记(KV Cache爆炸)。他们的办法叫 HiCache,思路很野——内存不够?那就把暂时不用的记忆先扔到CPU内存甚至硬盘里,用的时候再快速捞回来。这相当于给显存开了个虚拟内存,让长上下文处理稳多了。
-
让模型“秒换新脑”:训练Agent时需要频繁试错、更新模型权重。传统方法换一次“脑子”(权重)要等好几分钟,GPU干等着。他们搞了个 Mooncake 系统,把加载过程极度优化,现在给千亿模型换脑,最快能压到20秒内,几乎做到热插拔。
-
管住“磨洋工”的任务:Agent任务时长没准,一个慢任务能拖垮整个训练。他们通过全异步的调度机制,把慢任务隔离开,不让一颗老鼠屎坏了一锅粥。
三、我的看法:这事儿的味道变了
表面看,这是一次技术适配。但在我看来,这标志着国产算力生态玩法的彻底转变。
以前的感觉是:“我(硬件)在这了,你们(软件和开发者)快来适配我。”姿态比较高。
现在昇腾的做法是:“你们(SGLang社区)最需要什么?是应对高并发?好,我把HiCache优化跟上。需要热更新?我把Mooncake适配好。” 变成了 “贴身服务”。
这种转变非常关键。它意味着昇腾不再仅仅是一个需要额外费劲去支持的“硬件选项”,而是试图把自己变成开发流程里一个 “默认的、可靠的底座”。
说白了,当麻烦消失,选择才会真正发生。对于开发者和企业来说,成本一降,门槛一低,国产算力的实用价值才真正开始凸显。

SGLang 与昇腾合作
四、接下来可以关注什么?
这次合作成了,是因为软件生态和硬件工程都认清了现实:谁也离不开谁。这种“软硬深度捆绑”的模式,可能会是未来几年提升国产AI竞争力的主要路径。
你看好这种模式吗?或者你在模型部署中还遇到过哪些坑?
